ხშირია შემთხვევები, როდესაც ერთი და იგივე ვაკანსია რამდენიმე ვებ-გვერდზე ქვეყნდება. ამიტომ მონაცემთა თავმოყრისას საჭიროა მათი გაცხრილვა. ამ მიზნით სამი ძირითადი კრიტერიუმი შევარჩიეთ: ვაკანსიის დასახელება, დამსაქმებელი და ვაკანსიაზე განაცხადის შეტანის ბოლო ვადა. ამ კრიტერიუმებს თავისი დამატებითი ნიუანსები ახლავს.
- ვაკანსიის დასახელების და დამსაქმებლის ველების განხილვისას გასათვალისწინებელია, რომ jobs.ge-ზე ვაკანსიის დეტალები ძირითადად ქართულ და ინგლისურ ენებზე ქვეყნდება, hr.ge-ზე ერთ რომელიმე ენაზე, ხოლო hr.gov.ge-ზე მხოლოდ ქართულად. ამიტომ შედარებისას jobs.ge-ს ველების ორივე თარგმანს გამოვიყენებთ.
- არის შემთხვევები როდესაც ერთი და იგივე ვაკანსია ოდნავ განსხვავებული სახელწოდებით გვხვდება job.ge-ზე და hr.ge-ზე. მაგალითად, ერთგან შეიძლება შეგვხვდეს „კრედიტ-ოფიცერი“ და მდებარეობის ველში მითითებული იყოს ორი ან მეტი რეგიონი/ქალაქი, სადაც ვაკანსიაა გამოცხადებული, ხოლო მეორეგან „კრედიტ-ოფიცერი თბილისში, რუსთავსა და გორში“ და ვაკანსიის დასახელებაშივე იყოს ჩამოთვლილი მთელი რიგი რეგიონები/ქალაქები, სადაც ვაკანსიაა გამოცხადებული. თუმცა ასეთი შემთხვევები არც ისე ხშირია (სულ 15 შემთხვევა 17,000-ზე მეტი ვაკანსიიდან). ამიტომ ამ საკითხის გადაჭრა შემდეგი ეტაპისთვის გადავდეთ.
- ბოლო ვადის შემთხვევაში შევნიშნეთ, რომ ხშირად განცხადება რამდენიმე დღის „დაგვიანებით“ ქვეყნდება მეორე ვებ-გვერდზე. შესაბამისად, გამოქვეყნების თარიღიც და განაცხადის შეტანის ბოლო ვადაც რამდენიმე დღით არის ხოლმე გადაწეული. ამიტომ გადავწყვიტეთ, ბოლო ვადის ველში სამ- ან ნაკლებ-დღიანი აცდენა დასაშვებად ჩაგვეთვალა.
კრიტერიუმებს ვამოწმებთ ქვემოთ მოცემული ფუნქციის (R-ში) გამოყენებით.
add_row_to_df <- function(row, df, n = 4) {
index1 <- (row$position_cleaned == df$position_cleaned) |
(row$position_eng_cleaned == df$position_cleaned)
index1[is.na(index1)] <- FALSE
if (any(index1) == FALSE) {test <- FALSE} else {
df1 <- df[index1,]
index2 <- (row$employer_cleaned == df1$employer_cleaned) |
(row$employer_eng_cleaned == df1$employer_cleaned)
index2[is.na(index2)] <- FALSE
if (any(index2) == FALSE) {test <- FALSE} else {
df2 <- df1[index2,]
x <- row$ბოლო_ვადა[1]
if (is.na(x)) {test <- TRUE} else {
test <- any(abs(x - c(as.Date("01011900", format = '%d%m%Y'),
df2$ბოლო_ვადა[!is.na(df2$ბოლო_ვადა)])) < n)
}
}
}
return(!test)
}
ანუ, add_row_to_df(row, df) ამოწმებს ვაკანსია (row, ვთქვათ, jobs.ge-დან) ემთხვევა თუ არა არსებულ მონაცემთა ბაზაში (df ვთქვათ, hr.ge) რომელიმე ვაკანსიას. თუ ემთხვევა, ფუნქცია აბრუნებს FALSE-ს, რაც ნიშნავს, რომ row-ს ვაკანსია არ უნდა დავამატოთ მონაცემთა ბაზას. შესაბამისად, თუ არ ემთხვევა, ფუნქცია აბრუნებს TRUE-ს.
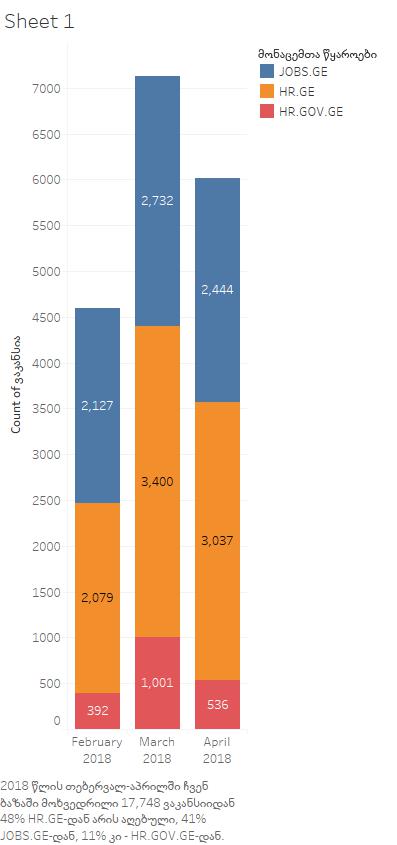
ასევე გადასაწყვეტია, განმეორებული ვაკანსიების წყვილებიდან (ან სამეულებიდან) რომელი დავტოვოთ ჩვენ მონაცემთა ბაზაში. როგორც მონაცემთა წყაროების აღწერაში ვახსენეთ, hr.ge-ზე jobs.ge-სთან შედარებით მეტი დეტალია ცალკე ველში მითითებული და, შესაბამისად, ადვილად მიკვლევადი. ხოლო, hr.gov.ge-ზე ყველაზე მეტი ინფორმაციაა მოცემული ასეთი “მზა სახით”. ამიტომ, განმეორებული ვაკანსიების შემთხვევაში უპირატესობას მივანიჭებთ პირველ რიგში hr.gov.ge-ს და შემდეგ hr.ge-ს.
მონაცემთა გაცხრილვის და თავმოყრისთვის გამოყენებული სრული კოდი ხელმისაწვდომია ჩვენ GitHub გვერდზე და თავსებადია მონაცემთა შესაგროვებლად გამოყენებულ კოდთან.